
1. Index
인덱스는 문서의 필드 값을 색인하여 콜렉션에서 데이터를 빠르게 탐색할 수 있도록 도와 빠른 쿼리 작업을 지원하고 데이터 정렬 및 집계 작업이 효율적으로 실행될 수 있도록 한다.
1) 정의
우리가 사전에서 단어를 빨리 찾을 수 있는 이유는 색인에 따른 정렬이 되어있기 때문이다. 데이터도 탐색을 효율적으로 하기위해 Index를 사용하여 효과적으로 데이터를 탐색할 수 있다.
MongoDB에서 Index는 B-tree와 같은 데이터 구조를 유지하여 필드의 값을 문서의 위치로 매핑한다. (키랑 주소만 저장하여 데이터를 매핑)
그래서 쿼리가 실행될 때, MongoDB는 전체 콜렉션을 검색할 필요 없이 인덱스를 사용하여 관련 문서를 찾을 수 있게 된다.
예를 들어, 사용자를 나타내는 문서의 콜렉션이 있고 각 문서에 age라는 필드가 있는 데이터 베이스가 있다. age 필드에 인덱스를 생성하게 되면 MongoDB는 모든 문서를 검사할 필요 없이 특정 나이를 가진 모든 문서를 효율적으로 찾을 수 있게 된다.
인덱스가 없다면, age가 30인 유저를 백만개의 데이터 중에서 찾을때 모든 콜렉션을 탐색한다.
그래서 총 125ms가 소요되는 것을 아래의 이미지에서 확인할 수 있다.
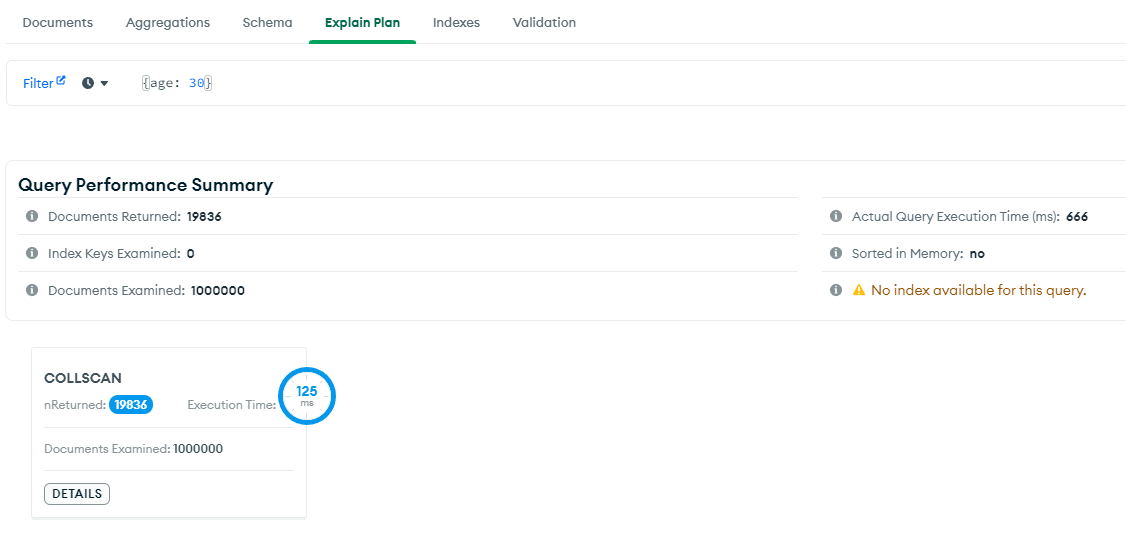
Index를 사용하면 총 10ms로 압도적으로 시간이 줄어드는 것을 확인할 수 있다. 인덱스를 사용하면, 모든 콜렉션을 탐색하는 것이 아니라 인덱스 정보를 Fetch하고 IXSCAN(인덱스 스캔)을 통해 데이터를 찾는 것을 확인할 수 있다.
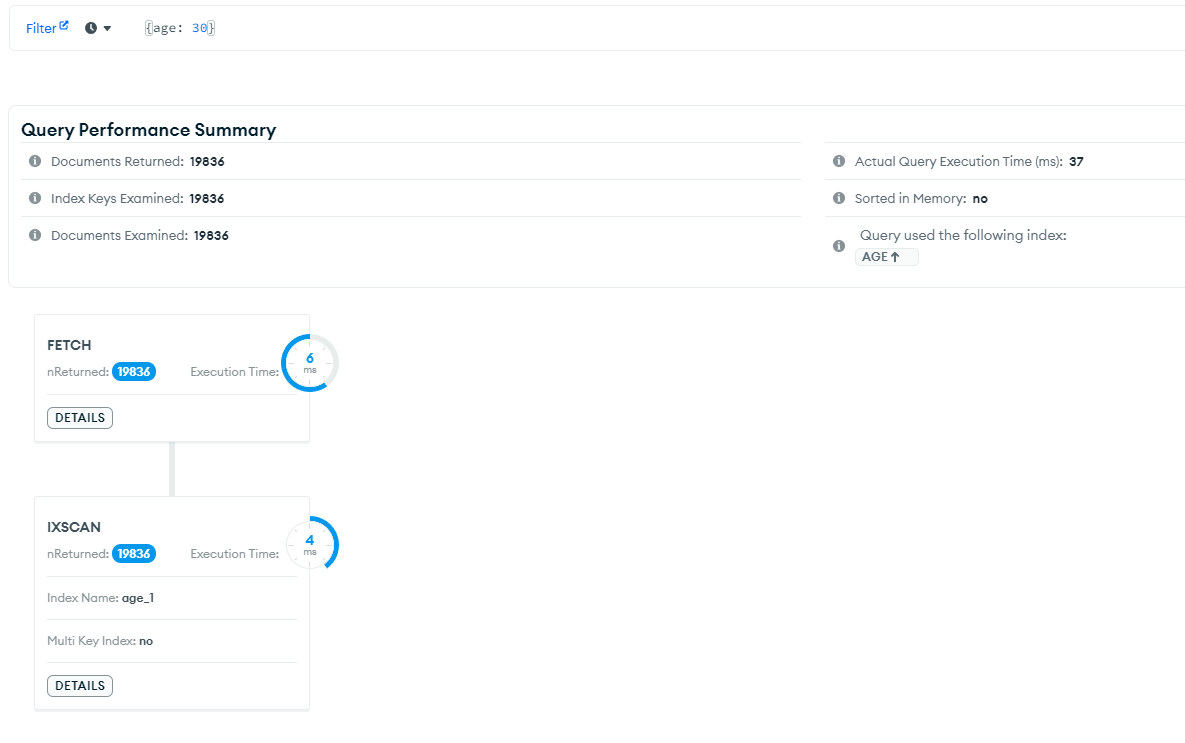
그러나 인덱스는 추가 디스크 공간을 사용하고, 각 문서에 기록할 때마다 관련 인덱스를 업데이트 해야하므로 쓰기 작업이 느려질 수 있다.
데이터를 생성할 때, Index도 생성하고 저장해야 하기 때문에 쓰기 작업이 느려진다.
- MongoDB는 모든 콜렉션에 대해
_id필드에 대한 인덱스를 자동으로 생성하여 각 문서에 고유 식별자가 있어 효율적으로 위치를 지정할 수 있다. unique한 값에도 자동으로 index가 생성된다. 왜냐하면 중복인지 아닌지 확인하기 위해서는 탐색을 해야하기 때문에 index가 필요한 것이다.
2) Index Selectivity
MongoDB의 Index Selectivity는 특정 인덱스가 얼마나 정확하게 데이터를 검색하는지를 나타내는 지표다.
Selectivity는 0에서 1 사이의 값으로 표시되며, 1에 가까울수록 인덱스의 검색 정확도가 높다.
인덱스의 Selectivity는 인덱스를 사용하여 검색할 때 검색하는 값의 유일성에 따라 결정된다.
예를 들어, 유일한 값이 있는 특정 필드에 대해서는 Selectivity가 1이 되어 검색 정확도가 높지만, 많은 값이 중복되는 필드에 대해서는 Selectivity가 낮아져 검색 정확도가 떨어질 수 있다.
MongoDB는 검색 성능을 향상시키기 위해 Selectivity가 높은 인덱스를 우선적으로 사용하도록 최적화되어 있어, Selectivity가 높은 인덱스를 사용하여 검색 쿼리를 작성하면 검색 성능이 향상될 수 있다.
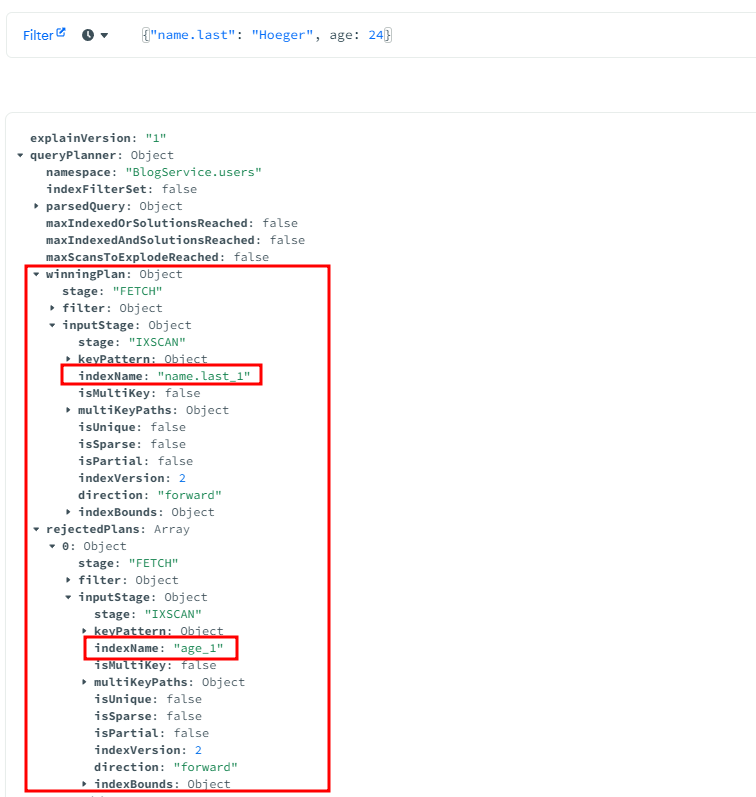
예를 들어, name.last에 대한 인덱스와 age에 대한 인덱스가 있는 데이터 베이스가 있다. 이 데이터 베이스에서{"name.last": "Hoeger", age: 24} 와 조건이 일치한 결과를 탐색한다면 어떤 인덱스를 활용할까?
이는 앞서 말했 듯, Selectivity가 높은 name.last 인덱스를 사용한다. (다양성이 더 많음)
3) 구현
MongoDB Compass에서 간단하게 Index를 생성 할 수도 있고, 코드로 생성할 수도 있다.
- Schema를 정의할 때, index 속성 사용
- Schema의 Index 메서드 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import { Schema, model, Types } from "mongoose";
import { CommentSchema } from "./Comment.js";
const BlogSchema = new Schema(
{
title: { type: String, required: true },
content: { type: String, required: true },
isLive: { type: Boolean, required: true, default: true },
user: {
// 1. index 속성으로 인덱스 생성
_id: { type: Types.ObjectId, required: true, ref: "user", index: true },
username: { type: String, required: true },
name: {
first: { type: String, required: true },
last: { type: String, required: true },
},
},
comments: [CommentSchema],
},
{ timestamps: true }
);
// 2. index 메서드로 인덱스 생성
// unique: true 속성을 줄 수도 있다.
BlogSchema.index({ updateAt: 1 });
BlogSchema.index({ updateAt: 1 }, { unique: true });
const Blog = model("blog", BlogSchema);
export default Blog;
2. CompoundKey
CompoundKey(복합키)란 다수의 필드를 포함하는 고유한 키로 한 개의 도큐먼트에서 각 필드 값의 조합이 고유하게 식별되어야 하는 경우 사용된다.
1) 정의
MongoDB에서는 도큐먼트의 각 필드 값을 결합하여 고유한 식별자를 생성할 수 있다.
예를 들어, 고객 정보를 저장할 때 고객의 이름과 주소를 결합한 값을 고유 식별자로 사용할 수있고 이를 CompoundKey라고 한다.
해당 키를 사용하여 고객의 이름과 주소를 기준으로 검색, 정렬한 데이터를 더 빠르게 얻을 수 있다.
- CompundKey의 원리는 각 필드 값을 결합하여 고유한 키를 생성한다.
- MongoDB는 BSON(Binary JSON) 형식으로 저장되는 도큐먼트를 사용하기 때문에 각 필드 값을 결합하여 고유한 식별자를 생성할 수 있다.
- BSON은 MongoDB에서 사용하는 데이터 형식으로 JSON 형식의 데이터를 이진 형식으로 저장한다.
- BSON은 더 빠르고 효율적으로 데이터를 저장, 전송할 수 있다.
CompoundKey를 다음과 같이 활용할 수 있다.
- 중복 데이터 방지: CompoundKey를 사용하면, 각 도큐먼트가 고유하게 식별되어 중복 데이터를 방지할 수 있다.
- 검색 성능 향상: CompoundKey 기반으로 검색할 수 있어 빠른 속도로 데이터를 조회할 수 있다.
- 데이터 구조 정의: CompoundKey를 통해 필드 값을 결합하여 원하는 키 구조를 생성할 수 있어 데이터 구조를 정의할 수 있다.
CompoundKey는 고유성, 성능, 유연성을 향상시킬 수 있는 기능으로 적절히 활용하면 더 효율적인 데이터 관리와 분석이 가능하다.
2) 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import { Schema, model, Types } from "mongoose";
import { CommentSchema } from "./Comment.js";
const BlogSchema = new Schema(
{
title: { type: String, required: true },
content: { type: String, required: true },
isLive: { type: Boolean, required: true, default: true },
user: {
_id: { type: Types.ObjectId, required: true, ref: "user" },
username: { type: String, required: true },
name: {
first: { type: String, required: true },
last: { type: String, required: true },
},
},
comments: [CommentSchema],
},
{ timestamps: true }
);
// CompoundKey index 생성
BlogSchema.index({ "user._id": 1, updateAt: 1 });
const Blog = model("blog", BlogSchema);
export default Blog;
3. textIndex
MongoDB에서 텍스트 검색을 위한 인덱스이다.
1) 정의
일반적인 B-Tree 인덱스는 숫자나 날짜와 같은 정수, 부동소수점 타입의 값을 인덱스하지만 textIndex는 텍스트 필드의 값을 인덱스하여 텍스트 검색 쿼리를 할 수 있다. 검색할 텍스트 필드의 모든 단어를 색인하고 단어의 빈도수와 위치 등의 정보를 포함하여 검색 결과의 정확도를 향상시킨다.
예를 들어, title에 특정 단어가 들어간 블로그 게시글을 찾으려고 한다면 textIndex를 title필드에 생성하여 아래의 이미지와 같이 데이터를 탐색할 수 있다.
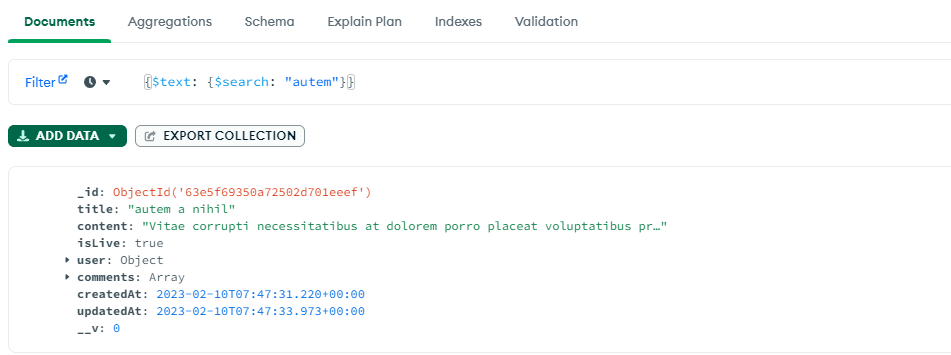
2) 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import { Schema, model, Types } from "mongoose";
import { CommentSchema } from "./Comment.js";
const BlogSchema = new Schema(
{
title: { type: String, required: true },
isLive: { type: Boolean, required: true, default: true },
_id: { type: Types.ObjectId, required: true, ref: "user" },
username: { type: String, required: true },
name: {
first: { type: String, required: true },
last: { type: String, required: true },
},
},
comments: [CommentSchema],
},
{ timestamps: true }
);
BlogSchema.index({ "user._id": 1, updateAt: 1 });
// text Index는 콜렉션에서 한개만 만들 수 있다.
BlogSchema.index({ title: "text" });
const Blog = model("blog", BlogSchema);
export default Blog;
- textIndex는 콜렉션에서 한 개만 만들 수 있기 때문에, 만약 content에 대한 textIndex도 추가하고 싶으면 복합 키를 만들면 된다.
BlogSchema.index({title: "text", content: "text"})